

Cache System Stability


In terms of cache stability, basically every cache-related article and share on the web talks about three key points.
- Cache penetration
- Cache Breakdown
- Cache Avalanche
Why talk about cache stability in the first place? You can recall when we introduce caching? Usually it is when the DB is under pressure or even frequently hit and hung that we introduce caching, so we first introduced the caching system to solve the stability problem.
Cache Penetration
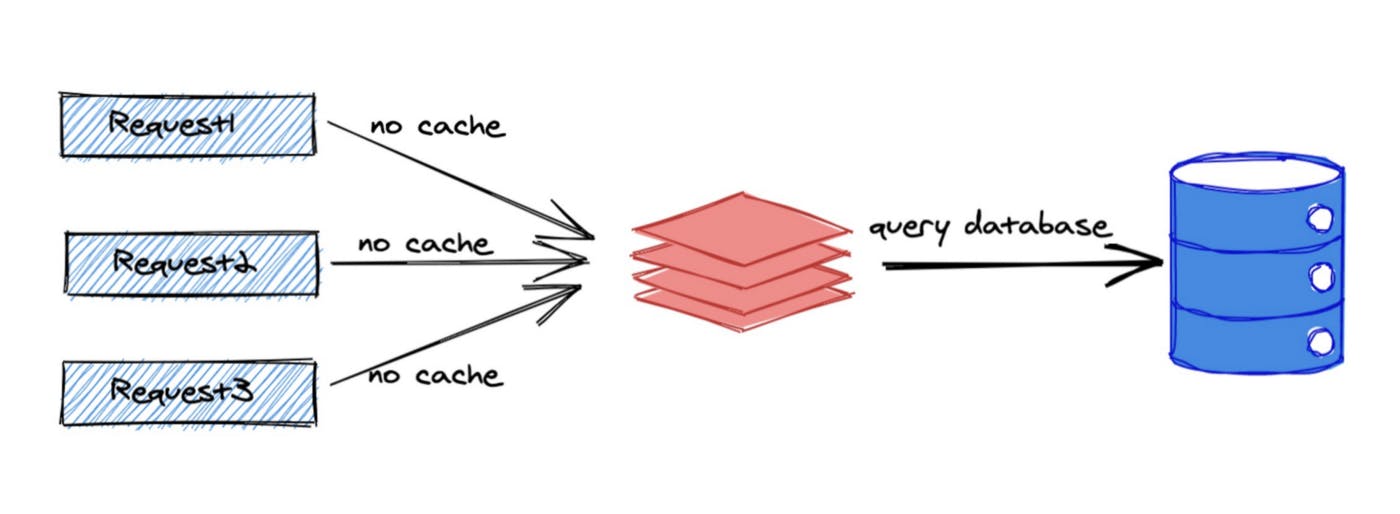
The reason for the existence of cache penetration is the request for non-existent data, from the figure we can see that request 1 for the same data will go to the cache first, but because the data does not exist, so there is certainly no cache, then it will fall to the DB, request 2 and request 3 for the same data will also fall to the DB through the cache, so when a large number of requests for non-existent data DB pressure will be particularly large, especially It is possible that malicious requests will break down (people with bad intentions will find a data does not exist and then launch a lot of requests for this non-existent data).
The solution of go-zero is that we also store a placeholder in the cache for non-existent data requests for a short time (say one minute), so that the number of DB requests for the same non-existent data will be decoupled from the actual number of requests, and of course, on the business side, we can also remove the placeholder when adding new data to ensure that the new data can be queried immediately.
Cache Breakdown
The reason of cache breakdown is the expiration of hot data, because it is hot data, so once it expires, there may be a lot of requests for the hot data at the same time, then if all the requests can't find the data in the cache, if they fall to the DB at the same time, then the DB will be under huge pressure instantly, or even directly stuck.
The solution of go-zero is: for the same data we can use core/syncx/SharedCalls to ensure that only one request falls to DB at the same time, other requests for the same data wait for the first request to return and share the result or error, depending on different concurrency scenarios, we can choose to use in-process locks (concurrency Not very high), or distributed locks (very high concurrency). If not particularly needed, we generally recommend in-process locks. After all, introducing distributed locks will increase complexity and cost, drawing on Occam's razor: do not add entities unless necessary.
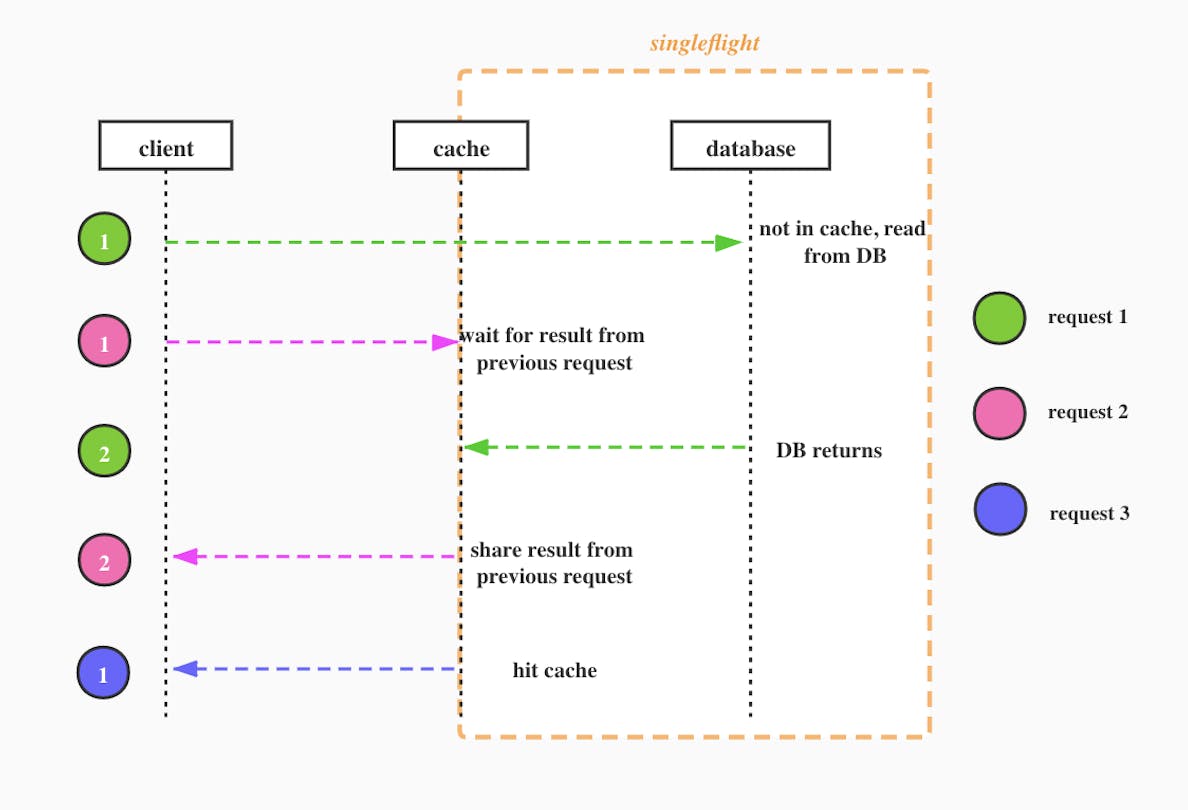
Let's take a look at the cache breakdown protection flow together in the figure above, where we use different colors to indicate different requests.
- Green request arrives first, finds no data in the cache, and goes to the DB to query
- The pink request arrives, requests the same data, finds the existing request is being processed, waits for the green request to return, singleflight mode
- The green request returns, the pink request returns with the result shared by the green request
- Subsequent requests, such as blue requests can fetch data directly from the cache
Cache Avalanche
The reason for cache avalanche is that a large number of simultaneously loaded caches have the same expiration time, and a large number of caches expire in a short period of time when the expiration time arrives, which will make many requests fall to the DB at the same time, thus causing the DB to spike in pressure or even get stuck.
For example, in the epidemic online teaching scenario, high school, middle school and elementary school are divided into several time periods to start classes at the same time, then there will be a large amount of data loaded at the same time and the same expiration time is set, when the expiration time arrives there will be a reciprocal DB request wave, such pressure wave will be passed to the next cycle, or even superimposed.
The solution of go-zero is.
- Use distributed cache to prevent cache avalanche caused by single point of failure
- Add a standard deviation of 5% to the expiration time. 5% is the empirical value of the p-value in the hypothesis test (interested readers can check it for themselves)
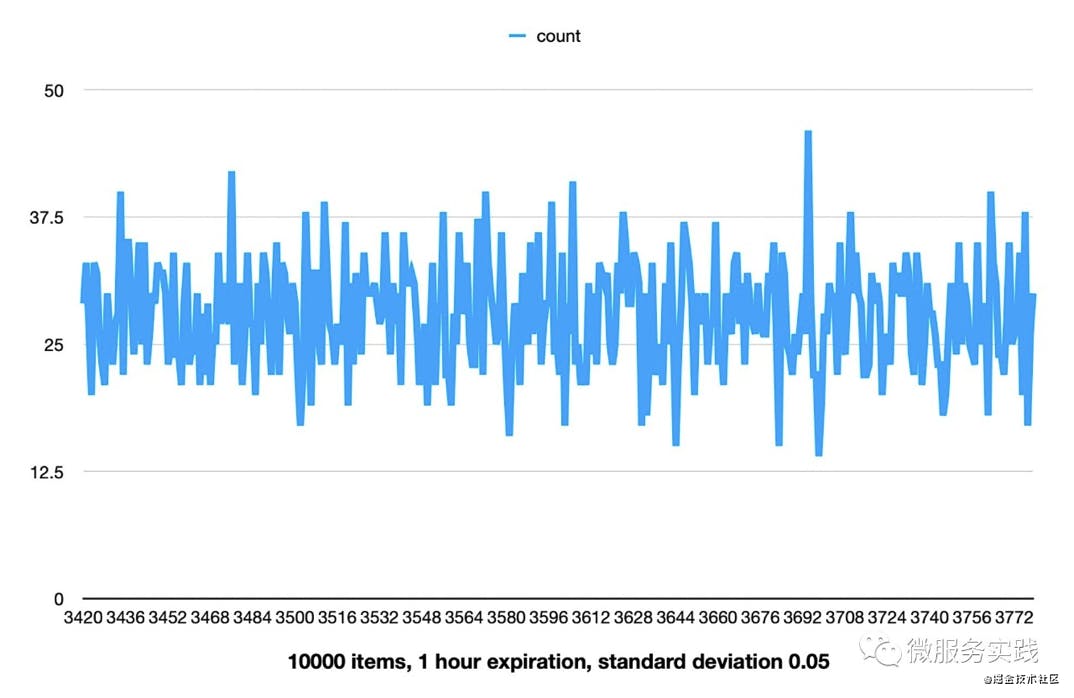
Let's do an experiment. If we use 10,000 data and the expiration time is set to 1 hour and the standard deviation is set to 5%, then the expiration time will be more evenly distributed between 3400 and 3800 seconds. If our default expiration time is 7 days, then it will be evenly distributed within 16 hours with 7 days as the center point. This would be a good way to prevent the cache avalanche problem.
Unfinished
In this article, we discussed common stability issues with caching systems, and in the next article I'll analyze cached data consistency issues with you.
The solutions to all these problems are included in the go-zero microservices framework, so if you want to get a better understanding of the go-zero project, feel free to go to the official website to learn about the specific examples.