Reduce Response Time with MapReduce
In microservice development, api gateways play the role of providing restful api to the outside world, and api data often depends on other services, and complex api will depend on multiple or even dozens of services. Although the time consumption of a single dependent service is generally low, if multiple services are serially dependent, then the time consumption of the entire api will be greatly increased.
So what is the means to optimize it? The first thing that comes to mind is to handle the dependencies in a concurrent manner so that the overall dependency time can be reduced, and the Go base library provides us with the WaitGroup tool for concurrency control, but the actual business scenario is that if one of the multiple dependencies goes wrong We expect to return immediately instead of waiting for all dependencies to finish executing and then return the result, and the assignment of variables in WaitGroup often requires locking, and each dependency function needs to add Add and Done for novices to be more error-prone.
Based on the above background, the go-zero framework provides us with a concurrency tool MapReduce, which works out of the box and does not require any initialization. Let's take a look at the following graph to see the time consumption comparison between using MapReduce and not using it:

For the same dependency, it takes 200ms to process serially, but the time taken with MapReduce is equal to 100ms, which means that MapReduce can greatly reduce the service time, and the effect will be more obvious as the dependency increases, reducing the processing time without increasing the pressure on the server.
Concurrent Processing Tools MapReduce
MapReduce is a software architecture proposed by Google for parallel computing of large-scale datasets, and the MapReduce tool in go-zero draws on this architectural idea
The MapReduce tool in the go-zero framework is mainly used for concurrent processing of bulk data to improve the performance of the service
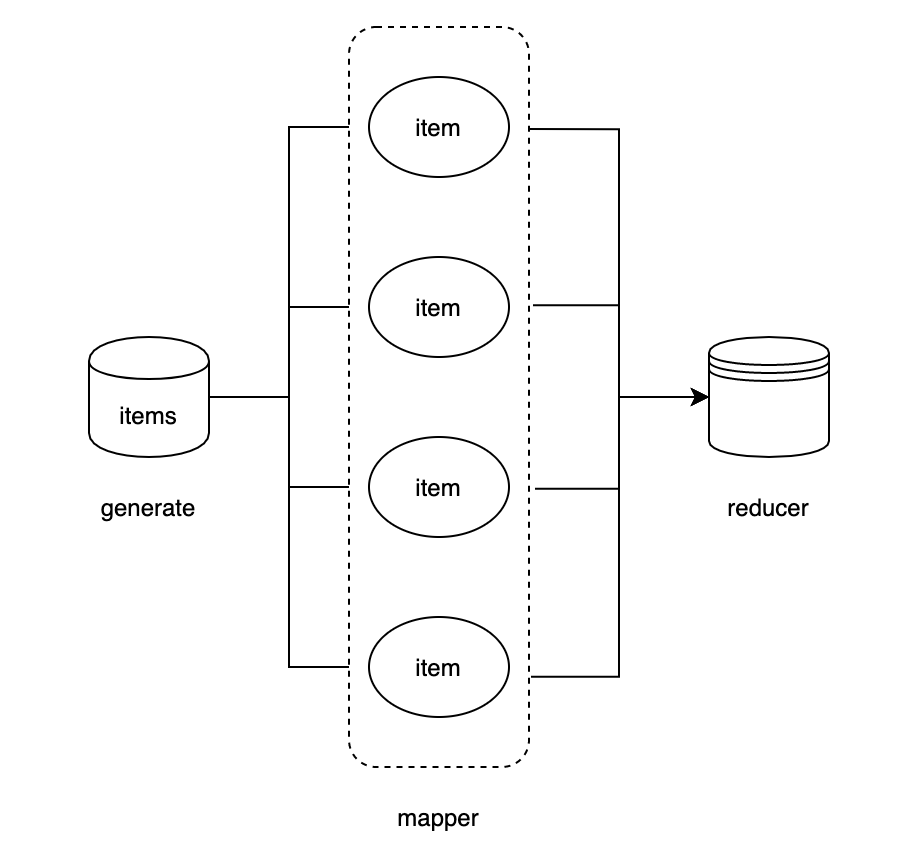
Let's demonstrate the usage of MapReduce with a few examples
MapReduce has three main parameters, the first parameter is generate to produce data, the second parameter is mapper to process the data, and the third parameter is reducer to aggregate the data after mapper and return it, and you can also set the number of concurrent threads through the opts option
Scenario 1: The results of certain functions often need to rely on multiple services, for example, the results of product details often rely on user services, inventory services, order services, etc., and generally the dependent services are provided in the form of rpc, in order to reduce the time consuming dependencies we often need to do parallel processing of dependencies
func productDetail(uid, pid int64) (*ProductDetail, error) {
var pd ProductDetail
err := mr.Finish(func() (err error) {
pd.User, err = userRpc.User(uid)
return
}, func() (err error) {
pd.Store, err = storeRpc.Store(pid)
return
}, func() (err error) {
pd.Order, err = orderRpc.Order(pid)
return
})
if err ! = nil {
log.Printf("product detail error: %v", err)
return nil, err
}
return &pd, nil
}
The example of returning product details relies on multiple services to get the data, so doing concurrent dependency processing is a big performance boost for the interface.
Scenario 2: Very often we need to process a batch of data, for example, for a batch of user ids, validate the legitimacy of each user and if there is an error in the validation process, the validation will fail and the returned result will be the validation of the legitimate user id
func checkLegal(uids []int64) ([]int64, error) {
r, err := mr.MapReduce(func(source chan<- interface{}) {
for _, uid := range uids {
source <- uid
}
}, func(item interface{}, writer mr.Writer, cancel func(error)) {
uid := item.(int64)
ok, err := check(uid)
if err ! = nil {
cancel(err)
}
if ok {
writer.Write(uid)
}
}, func(pipe <-chan interface{}, writer mr.Writer, cancel func(error)) {
var uids []int64
for p := range pipe {
uids = append(uids, p.(int64))
}
writer.Write(uids)
})
if err ! = nil {
log.Printf("check error: %v", err)
return nil, err
}
return r.([]int64), nil
}
func check(uid int64) (bool, error) {
// do something check user legal
return true, nil
}
In this example, if there is an error in the check process, the check process will be ended by the cancel method, and error will be returned, and if a uid is false, the final result will not return the uid.
MapReduce usage notes
- Both mapper and reducer can call cancel with the parameter error, which returns immediately after the call and returns the result as nil, error
- Write is not called in the mapper, the item will not be aggregated by the reducer.
- Write is not called in the reducer, the result is nil, ErrReduceNoOutput.
- The reducer is single-threaded, and all the results from the mapper are aggregated serially here
Implementation principle analysis:
MapReduce first generates data through the buildSource method by executing generate (parameter is unbuffered channel) and returns the unbuffered channel from which the mapper will read data
func buildSource(generate GenerateFunc) chan interface{} {
source := make(chan interface{})
go func() {
defer close(source)
generate(source)
}()
return source
}
The cancel method is defined in the MapReduceWithSource method, which can be called in both mapper and reducer, and will return immediately after the main thread receives the close signal
cancel := once(func(err error) {
if err ! = nil {
retErr.Set(err)
} else {
// default error
retErr.Set(ErrCancelWithNil)
}
drain(source)
// call close(ouput) The main thread receives the Done signal and returns immediately
finish()
})
In the mapperDispatcher method is called executeMappers, executeMappers consume the data generated by buildSource, each item will start a separate goroutine processing, the default maximum number of concurrency is 16, can be set by WithWorkers
var wg sync.WaitGroup
defer func() {
wg.Wait() // make sure all items are processed
close(collector)
}()
pool := make(chan lang.PlaceholderType, workers)
writer := newGuardedWriter(collector, done) // write mapper's finished data to collector
for {
select {
case <-done: // When cancel is called it will trigger an immediate return
return
case pool <- lang.Placeholder: // control the maximum number of concurrent events
item, ok := <-input
if !ok {
<-pool
return
}
wg.Add(1)
go func() {
defer func() {
wg.Done()
<-pool
}()
mapper(item, writer) // process the item and call writer.Write to write the result to the corresponding channel in the collector
}()
}
}
The reducer single goroutine processes the data written to the collector by the mapper, and if the reducer does not call writer.Write manually, it will eventually execute the finish method to close the output to avoid deadlocks
go func() {
defer func() {
if r := recover(); r ! = nil {
cancel(fmt.Errorf("%v", r))
} else {
finish()
}
}()
reducer(collector, writer, cancel)
}()
The toolkit also provides a number of methods for different business scenarios, the implementation principle is similar to MapReduce, interested students can view the source code to learn
- The MapReduceVoid function is similar to MapReduce but returns no results, only error.
- Finish handles a fixed number of dependencies, returns error, and returns an error immediately
- FinishVoid is similar to Finish method, no return value
- Map only does generate and mapper processing, returns channel
- MapVoid and Map function is similar, no return
This article introduces the MapReduce tool in the go-zero framework, which is very practical in real projects. Using the tools well can be of great help to improve service performance and development efficiency, so I hope this article can bring you some gains.
Project address
https://github.com/zeromicro/go-zero
Welcome to use and give a star!